
류동균의 R 공부방입니다.
로지스틱 회귀분석(Logistic Regression Analysis) 본문
머신러닝기법에는 로지스틱 회귀분석(Logistic Regression Analysis)라는 것이 있다.

간단하게 설명하자면 위와같은 선형데이터를 분류할때 다음과같이 분류하는 선형분류기를
로지스틱 회귀분석 모델이라고 한다.
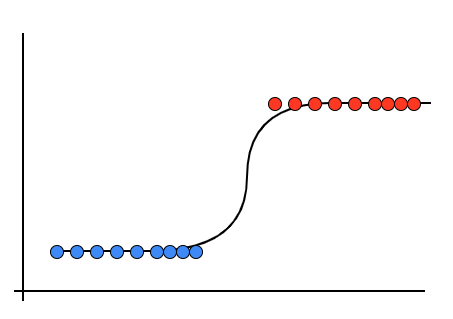
로지스틱회귀분석을 공부하기위해 iris데이터로 4가지의 컬럼으로 붓꽃의 종류를
분류하는 작업을 해볼 예정이다.
로지스틱회귀분석을 하기에 앞서 몇가지알아야 할 점이 있다.
##Traning, Test Set

회귀분석 모델을 만들때는 현실데이터를 7:3 혹은 8:2 비율로 traning set과 test set으로 나누어
traning set으로 만든 모델으로 test set 에 test를 하여 결과가 적합한지를 알아보아야한다.
## Outlier 이상치

정확한 모델을 만들기 위해 이상치를 제거해야하는데 이상치를 판단하는 기준은 다음과 같다.
#도메인지식, 데이터 파악, boxplot및 3시그마
예를들어 옷을 만들때 한국인의 키, 몸무게, 어깨, 가슴, 허리 사이즈 등 을 기반으로 옷의 사이
별 치수를 정의해야할 때, 각각의 변수들이 상관관계를 가지게 되는데 일반적으로 키가 크면
무게가 많이나가고 어깨, 가슴, 허리 사이즈가 크기 마련이다. 그러나 이는 평균일뿐 키가 190
이지만 60kg이 나가거나 키가 160이지만 90kg가 나가는 등 모델 형성에
올바른 모델형성에 영향을 주는 데이터들을 이상치라고 가정하고 이 값들을 제거해야한다.
그럼 이제 iris데이터로 logistic regression을 시작해보자.
쉽게 해보기 위해 우선 Species는 versicolor를 제외한 2개의 Species로 traning set과 test set의
비율은 7:3으로 진행해볼 예정이다. iris의 경우 이상치는 따로 존재하지 않음으로 생략한다.
##데이터 준비하기
#필요한 패키지
library(dplyr)
#sample_data 설정
sample_data <- iris$Species
#데이터 설정
df <- iris
# versicolor를 제외한 iris데이터 df화
df <- df %>%
filter(Species != "versicolor") %>%
as.data.frame()
# Species의 팩터에서 versicolor를 제외시키기위해 재설정
df$Species <- factor(df$Species)
# traning_sampling_index추출
training_sampling <- sort(sample(1:nrow(df), nrow(df) * 0.7 ))
# test_sampling_index추출 setdiff()는 차집합함수
test_sampling <- setdiff(1:nrow(df),traning_sampling)
#traning_set
training_set <- df[training_sampling,]
#test_set
test_set <- df[test_sampling,]
#plot으로 전체적인 데이터파악
plot(training_set)
위와 같이 실행했다면 다음과 같은 그래프가 나올것이다.
그래프를 간단히 보면 Sepal.Width를 제외하고는 대체적으로 Species에 따라 값이 2가지의
구간으로 분류가 되는 경향이 있다고 볼 수 있다.
그러므로 Sepal.Width를 제외하고 나머지를 독립변수로 설정하여 모델을 만들어 보도록 하자.
## logistic model
# 로지스틱 기본 함수
# glm(종속변수 ~ 독립변수, data = df, family="binomial")
# 모델생성
logit_m <- glm(Species ~ Sepal.Length + Petal.Length + Petal.Width, data = training_set, family = "binomial")
# 모델확인
logit_f <- fitted(logit_m)다음과 같이 로지스틱회귀 모델을 만들고 모델을 확인해 보았다.
이번에는 모델의 정확도를 확인해보자
##정확성 확인
# 통상적으로 2가지로 분류할때 0.5를 기준으로 나눈다.
logit_f < 0.5
# factor를 1,2 numeric으로 변환
df$Species %>% as.numeric()
# 모델을 ifelse를 사용해 df$Species %>% as.numeric()의 결과와 동일한 형식으로 나오게 1, 2로 분류
ifelse(logit_f < 0.5, 1, 2)
# 정확도를 위한 데이터 생성
is_correct <- training_set$Species %>% as.numeric() == ifelse(logit_f < 0.5, 1, 2)
# 정확도
sum(is_correct) / length(is_correct)다음과 같이 한다면 iris데이터의 경우 분류가 확실한 데이터라 정확도가 1이거나
1에 매우 가깝게 나올 것이다.
이는 모델의 신뢰도가 매우높음을 보여준다.
이제는 traning set이 아닌 test set에 모델을 적용시켜 정확도를 알아보자.
##test_set에 모델 적용
# predict()
# 기본형 predict(모델, 데이터, type = "response")
logit_p <- predict(logit_m, test_set, type = "response")
# 정확도 데이터
is_correct_p <- (test_set$Species %>% as.numeric()) == ifelse(logit_p < 0.5, 1,2)
# 정확도
sum(is_correct_p) / length(is_correct_p)test set에 적용한 모델의 정확도를 확인해보면 역시 1이나 1과 매우 가깝게 나오는 것을
확인 할 수 있다.
이는 traning set으로 만든 모델이 신뢰성이 매우 높다는 것을 보여준다.
그러면 logistic regression을 알아봤으니 iris데이터에서 versicolor라는 Species를 제외하지 않고
multi logistic regression을 해보자.
##traning, test set
#신경망 패키지 neural network
library(nnet)
#df 설정
df <- iris
#sampling index
training_sampling <- sort(sample(1:nrow(df), nrow(df) * 0.7 ))
test_sampling <- setdiff(1:nrow(df),training_sampling)
#training_set, test_set
training_set <- df[training_sampling,]
test_set <- df[test_sampling,]
traning set과 test set을 준비했으니 모델을 만들어보자.
multi logistic regression에서는 multinom()이라는 함수를 사용해 모델을 생성한다.
## multi logistic regression model
multi_logit_m <- multinom(Species ~ Sepal.Length + Petal.Length + Petal.Width, data = training_set)
fitted(multi_logit_m)
이제 test set에 모델을 적용시켜 모델의 정확도를 판단해보자.
## model acurrcy
# test set에 모델 적용
multi_logit_p <- predict(multi_logit_m, newdata = test_set, type = "class")
# 정확도
is_correct_m <- sum(multi_logit_p == test_set$Species) / nrow(test_set)
# 결과
xtabs(~ multi_logit_p + test_set$Species)sampling을 할때마다 다르겠지만 정확도는 0.977778 로 매우 높게 나왔다.
그림과 같이 xtabs()를 실행시켜보았을때 virginica를 versicolor로 잘못 분류한것 1개의 row를
제외하고는매우 높은 확률로 Sepal.Length, Petal.Length, Petal.Width 3개의 feature로 Species를
추정할 수 있었다.

이렇게 간단하게 iris데이터를 가지고 logistic regressiom을 해보았다.
iris 데이터의 경우 이상치가 없고 분류가 딱나뉘어 학습하기에는 좋은 데이터였다.
그러나 실무에서라면 10개 혹은 그이상의 많은 변수들이 있기때문에
도메인 지식을 통한 정확한 이상치 제거 및 데이터 파악을 통해 올바른 logistic model을
만들 수 있다고 생각한다.
'Machine Learning' 카테고리의 다른 글
| K-최근접 이웃(K-Nearest Neighbor) (0) | 2019.09.25 |
|---|---|
| 뉴럴 네트워크(Neural Network) (0) | 2019.09.24 |
| 랜덤 포레스트(Random Forest) (0) | 2019.09.22 |
| 의사결정 나무(Decision Tree) (0) | 2019.09.20 |
| 선형회귀 분석(Linear regression analysis) (0) | 2019.09.16 |



